
 Years ago the biggest challenge in static code analysis was trying to find more and more interesting things. In our original CodeWizard product back in the early 90’s, we had 30 some-odd rules based on items from Scott Meyers‘ book “Effective C++“. It was what I link to think of as “Scared Straight” for programmers. Since then static analysis researchers have constantly worked to push the envelope of what can be detected, including adding newer techniques like data flow analysis to expand what static analysis can do.
Years ago the biggest challenge in static code analysis was trying to find more and more interesting things. In our original CodeWizard product back in the early 90’s, we had 30 some-odd rules based on items from Scott Meyers‘ book “Effective C++“. It was what I link to think of as “Scared Straight” for programmers. Since then static analysis researchers have constantly worked to push the envelope of what can be detected, including adding newer techniques like data flow analysis to expand what static analysis can do.
It seems to me that the biggest challenge currently is not to keep adding new weakness to detect, although I hope at some point we can again return to that. Today one of the most common hurdles people run into is trying to make sense of the results they get. Although people do day “I wish static analysis would catch ____” (name your favorite unfindable bug), it’s far more common to say “Wow, I have way too many results, static analysis is noisy” and “static analysis is full of false positives”. Some companies have gone so far as to put triage into their workflow, having recognized that the results they produce aren’t exactly what developers need.
So while what developers seem to be saying is there are too many results, the most common statements are “it’s noisy” are even more commonly “It’s a false positive”. But what IS a false positive in static analysis?
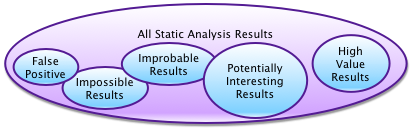
Universe of static analysis results
The term or idea of a false positive seems to have two meanings. In the simplest sense, it means that the message that a rule was violated is incorrect, or in other words the rule was not violated – the message was false. Sometimes developers fall into the trap of labeling any error message they don’t like as a false positive, but this isn’t really correct. They may label it a false positive because they simply don’t agree with the rule, they may label it because they don’t understand how it applies in this situation, or they may label it because they don’t think it’s important in general or in this particular case.
False positives and “true” positives are in two different areas. One is pattern based static analysis, which also includes metrics. There is also flow-based static analysis. One thing to remember is that pattern based static analysis doesn’t have false positives, it’s really a bug in the rule, because the rule should not be ambiguous. If the rule doesn’t have a clear pattern to look for, it’s a bad rule.
This doesn’t mean that when a rule lists a violation that there is a bug, which is important to note. A violation simply means that the pattern was found, indicating a weakness in the code, a susceptibility if you will to having a bug. Once you recognize the difference between a bug and a potential bug or weakness, then you realize that looking for these patterns because they are dangerous to your code.
When I look at violation, I ask myself, does this apply to my code, or doesn’t it apply? If it applies, I fix the code, if it doesn’t apply I suppress it. It’s best to suppress it in the code directly so that it’s visible and others can look at it, and you won’t end up having to review it a second time.
It’s a bad idea to not suppress the violation explicitly, because then you will constantly be reviewing the same violation. Think of using a spell checker but never adding your words to it’s dictionary. The beauty of in-code suppression is that it’s independent of the engine. Anyone can look at the code and see that the code has been reviewed and that this pattern is deemed acceptable in this code.
In flow analysis you have to address false positives because it is in the nature of flow analysis to have false positives. Flow analysis cannot avoid false positives, for the same reason unit testing cannot generate perfect unit test cases. The analysis has to make determinations about expected behavior of the code, sometimes there are too many options to know what is realistic, or sometimes you simply don’t have enough information about what is happening in other parts of the system.
The important thing here is that the true false positive is once again something that is just completely wrong. For example the tool you’re using says you’re reading a null pointer. If you look at the code and see that it’s actually impossible, then you have a false positive.
If on the other hand, you simply aren’t worried about nulls in this piece of code because they’re handled elsewhere, then the message while not important is not a false positive. The messages range from “true and important” through “true and unimportant” and “true and improbable” to “untrue” – there is a lot of variation and they get handled differently.
There is a common trap here as well. As in the null example above, you may believe that a null value cannot make it to this point, but the tool found a way to make it happen. You want to be very sure to check and possibly to protect against this if it’s important to your application.
It’s critical to understand there there is both power and weakness in flow analysis. The power of flow analysis is that it goes through the code and tries to find hot spots and find problems around the hot spots. The weakness is that it is going some number of steps around the code it’s testing, like a star pattern.
The problem is that if you start thinking you’ve cleaned all the code because your flow analysis is clean, you are fooling yourself. Really, you’ve found some errors and you should be grateful for that.
In addition to flow analysis you should really think about using runtime error detection. Runtime error detection allows you to find much more complicated problems than flow analysis can find, and you have the confidence that the condition actually occurred, simply because it did. Runtime error detection doesn’t have false positives in the way that static analysis does.
One other important context to consider – is it worth the time. My approach to false positives is this: If it takes 3 days to fix a bug, it’s better to spend 20 minutes to look at a false positive, as long as I can tag it and never have to look at the same issue again. It’s a matter of viewing it in the right context. If you have a problem, for example with threads. Problems with threads are dramatically difficult to discover. If you want to find an issue related to threads it might take you weeks to track it down. I’d prefer to write the code in such a way that problems cannot occur in the first place. IE move my process from detection to prevention.
Your runtime rule set should closely match your static analysis rule set. They can find the same kinds of problems, but the runtime analysis has a massive number of paths available to it. This is because at runtime stubs, setup, initialization, etc are not a problem. The only limit is it only checks the paths your test suite happens to execute.
It’s very important that static analysis doesn’t overrun people. This means that you need to make sure that the number of errors you report to people is reasonable – if you start to overrun them with errors you’ll have a problem. One of the most common problems with static analysis is starting with a set of rules that is too big. The first step in static analysis is to setup the right set of rules. Make sure that each of the rules is something that your developers will be glad they got a message about, rather than annoyed. You want the reaction of “wow, I’m glad the tool found that for me”, not a reaction that says “Ugh, another stupid static analysis error that doesn’t matter.”
It’s better to start with a single rule that everyone thinks is wonderful than have a comprehensive rule set that checks for everything under the sun. Pay attention to feedback on static analysis rules you’re using. If you find a lot of people are questioning the same rule, or that it frequently has suppressions, it’s a good idea to review that rule and decide whether it’s really appropriate at this time. The rule-of-thumb you can use is “would I fix the code if I found this error”. If not, the configuration needs to change.
There are other configuration options that will affect the perception of false-positives and thus the adoption rate, besides just the particular rules you choose. Some rules might be appropriate for new code, but not for legacy code. It’s important to setup cut-off dates for legacy code that match what your policy is. If you have a policy that you only touch the lines in the code related to a bug, then your static analysis needs to match that. If you have a policy that says “fix all static analysis when you work on a file” then your configuration should match that.
A simple trap to avoid is not to bother checking things you aren’t planning on fixing. This sounds simple but is surprisingly typical. For example, there is a rule that you really like and you would like to have code compliant with it someday. Right now you’re not willing to stop a release, or fight with the team, etc to get compliance, but you really want to use the rule someday. The best idea is wait until that day. For now, do only rules you care about, then no one gets overwhelmed and you don’t send a mixed message on static analysis.
Another common trap is running on legacy code where you don’t plan fixing violations, or even won’t allow it because of the possibility of problems introduced by changing the code. Put simply, don’t bother testing something you’re not going to fix.
Static analysis when deployed properly doesn’t have to be a noisy unpleasant experience. Make sure your deployment goes right.
Resources
Pingback: Application Security IS a Quality Problem: 6 Testing Tips to Benefit Both Quality and Security – Parasoft
Pingback: Application Security IS a Quality Problem: 6 Testing Tips to Benefit Both Quality and Security