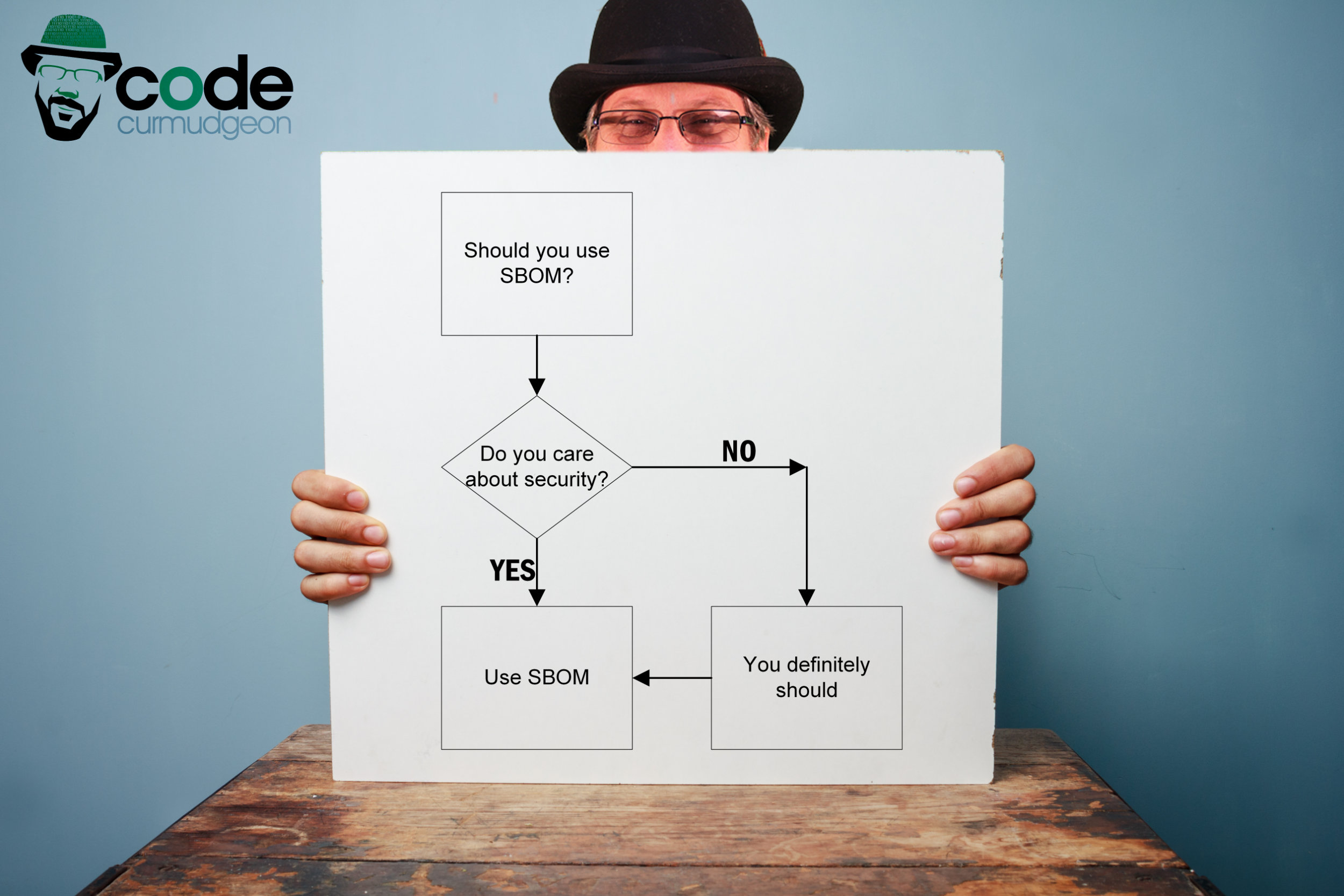
How to know when you need SBOM Posted on February 19, 2021 by Code Curmudgeon Just for grins – people say I probably talk about Software Bill of Materials or SBOM too much. It’s definitely something I think will...
AI Ethics and the Three Laws of Robotics Posted on January 9, 2020 by Code Curmudgeon After my previous video about AI and the trolley I had a pretty interesting discussion with a few people about the topic. While some...
Do AI Ethics Really Matter Posted on December 9, 2019 by Code Curmudgeon It seems like the issue of AI ethics, especially as it relates to autonomous driving, is the great zombie topic of software today… it...
CWE Top 25 2019 and On the Cusp Posted on November 21, 2019 by Code Curmudgeon The CWE Top 25 has been updated for 2019. It’s the first change to this important list of cybersecurity issues since 2011. They also...